Spark简介
This article is copied from the BerkeleyX: CS105x Introduction to Apache Spark course materials.
Source: https://raw.githubusercontent.com/spark-mooc/mooc-setup/master/cs105_lab1a_spark_tutorial.dbc

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
![]()
![]()
Spark Tutorial: Learning Apache Spark
This tutorial will teach you how to use Apache Spark, a framework for large-scale data processing, within a notebook. Many traditional frameworks were designed to be run on a single computer. However, many datasets today are too large to be stored on a single computer, and even when a dataset can be stored on one computer (such as the datasets in this tutorial), the dataset can often be processed much more quickly using multiple computers.
Spark has efficient implementations of a number of transformations and actions that can be composed together to perform data processing and analysis. Spark excels at distributing these operations across a cluster while abstracting away many of the underlying implementation details. Spark has been designed with a focus on scalability and efficiency. With Spark you can begin developing your solution on your laptop, using a small dataset, and then use that same code to process terabytes or even petabytes across a distributed cluster.
During this tutorial we will cover:
- Part 1: Basic notebook usage and Python integration
- Part 2: An introduction to using Apache Spark with the PySpark SQL API running in a notebook
- Part 3: Using DataFrames and chaining together transformations and actions
- Part 4: Python Lambda functions and User Defined Functions
- Part 5: Additional DataFrame actions
- Part 6: Additional DataFrame transformations
- Part 7: Caching DataFrames and storage options
- Part 8: Debugging Spark applications and lazy evaluation
The following transformations will be covered:
select(),filter(),distinct(),dropDuplicates(),orderBy(),groupBy()
The following actions will be covered:
first(),take(),count(),collect(),show()
Also covered:
cache(),unpersist()
Note that, for reference, you can look up the details of these methods in the Spark’s PySpark SQL API
**Part 1: Basic notebook usage and Python integration **
(1a) Notebook usage
A notebook is comprised of a linear sequence of cells. These cells can contain either markdown or code, but we won’t mix both in one cell. When a markdown cell is executed it renders formatted text, images, and links just like HTML in a normal webpage. The text you are reading right now is part of a markdown cell. Python code cells allow you to execute arbitrary Python commands just like in any Python shell. Place your cursor inside the cell below, and press “Shift” + “Enter” to execute the code and advance to the next cell. You can also press “Ctrl” + “Enter” to execute the code and remain in the cell. These commands work the same in both markdown and code cells.
|
|
(1b) Notebook state
As you work through a notebook it is important that you run all of the code cells. The notebook is stateful, which means that variables and their values are retained until the notebook is detached (in Databricks) or the kernel is restarted (in Jupyter notebooks). If you do not run all of the code cells as you proceed through the notebook, your variables will not be properly initialized and later code might fail. You will also need to rerun any cells that you have modified in order for the changes to be available to other cells.
|
|
(1c) Library imports
We can import standard Python libraries (modules) the usual way. An import statement will import the specified module. In this tutorial and future labs, we will provide any imports that are necessary.
|
|
Part 2: An introduction to using Apache Spark with the PySpark SQL API running in a notebook
Spark Context
In Spark, communication occurs between a driver and executors. The driver has Spark jobs that it needs to run and these jobs are split into tasks that are submitted to the executors for completion. The results from these tasks are delivered back to the driver.
In part 1, we saw that normal Python code can be executed via cells. When using Databricks this code gets executed in the Spark driver’s Java Virtual Machine (JVM) and not in an executor’s JVM, and when using an Jupyter notebook it is executed within the kernel associated with the notebook. Since no Spark functionality is actually being used, no tasks are launched on the executors.
In order to use Spark and its DataFrame API we will need to use a SQLContext. When running Spark, you start a new Spark application by creating a SparkContext. You can then create a SQLContext from the SparkContext. When the SparkContext is created, it asks the master for some cores to use to do work. The master sets these cores aside just for you; they won’t be used for other applications. When using Databricks, both a SparkContext and a SQLContext are created for you automatically. sc is your SparkContext, and sqlContext is your SQLContext.
(2a) Example Cluster
The diagram shows an example cluster, where the slots allocated for an application are outlined in purple. (Note: We’re using the term slots here to indicate threads available to perform parallel work for Spark. Spark documentation often refers to these threads as cores, which is a confusing term, as the number of slots available on a particular machine does not necessarily have any relationship to the number of physical CPU cores on that machine.)
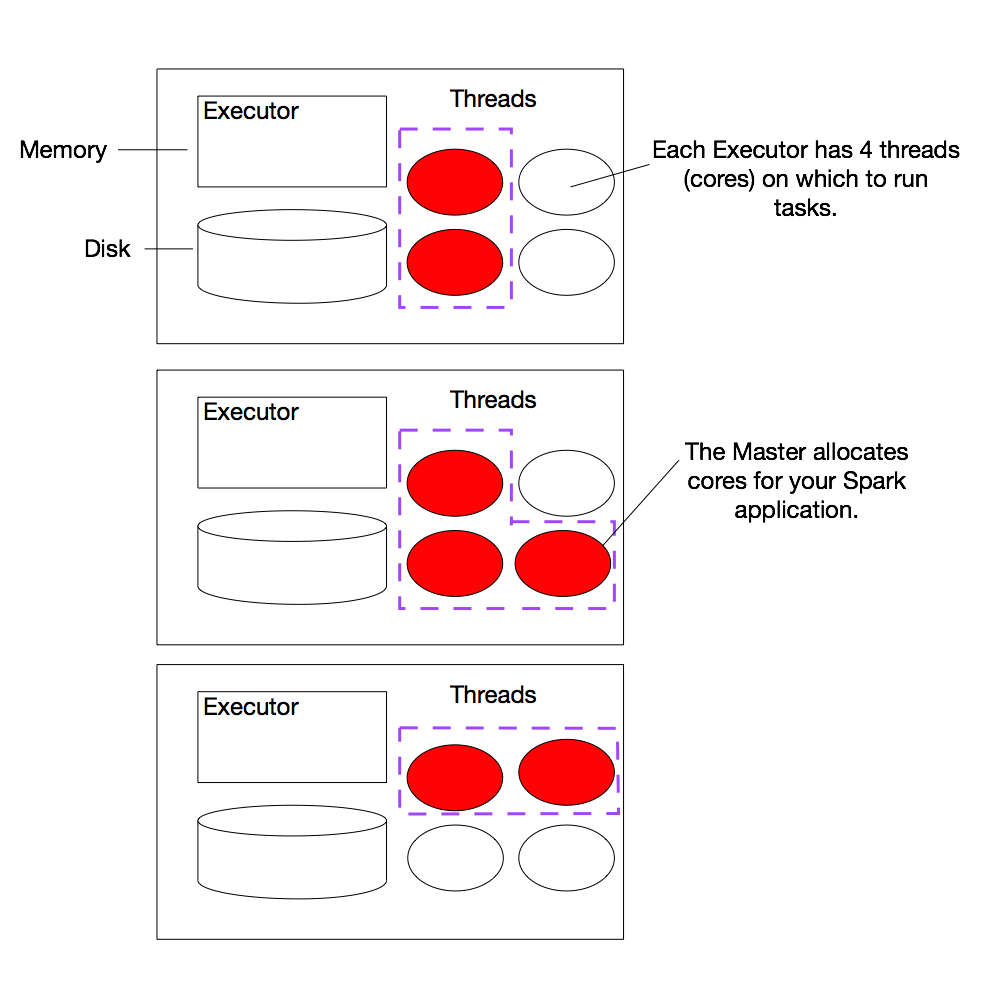
You can view the details of your Spark application in the Spark web UI. The web UI is accessible in Databricks by going to “Clusters” and then clicking on the “Spark UI” link for your cluster. In the web UI, under the “Jobs” tab, you can see a list of jobs that have been scheduled or run. It’s likely there isn’t any thing interesting here yet because we haven’t run any jobs, but we’ll return to this page later.
At a high level, every Spark application consists of a driver program that launches various parallel operations on executor Java Virtual Machines (JVMs) running either in a cluster or locally on the same machine. In Databricks, “Databricks Shell” is the driver program. When running locally, pyspark is the driver program. In all cases, this driver program contains the main loop for the program and creates distributed datasets on the cluster, then applies operations (transformations & actions) to those datasets.
Driver programs access Spark through a SparkContext object, which represents a connection to a computing cluster. A Spark SQL context object (sqlContext) is the main entry point for Spark DataFrame and SQL functionality. A SQLContext can be used to create DataFrames, which allows you to direct the operations on your data.
Try printing out sqlContext to see its type.
|
|
Note that the type is HiveContext. This means we’re working with a version of Spark that has Hive support. Compiling Spark with Hive support is a good idea, even if you don’t have a Hive metastore. As the
Spark Programming Guide states, a HiveContext “provides a superset of the functionality provided by the basic SQLContext. Additional features include the ability to write queries using the more complete HiveQL parser, access to Hive UDFs [user-defined functions], and the ability to read data from Hive tables. To use a HiveContext, you do not need to have an existing Hive setup, and all of the data sources available to a SQLContext are still available.”
(2b) SparkContext attributes
You can use Python’s dir() function to get a list of all the attributes (including methods) accessible through the sqlContext object.
|
|
(2c) Getting help
Alternatively, you can use Python’s help() function to get an easier to read list of all the attributes, including examples, that the sqlContext object has.
|
|
Outside of pyspark or a notebook, SQLContext is created from the lower-level SparkContext, which is usually used to create Resilient Distributed Datasets (RDDs). An RDD is the way Spark actually represents data internally; DataFrames are actually implemented in terms of RDDs.
While you can interact directly with RDDs, DataFrames are preferred. They’re generally faster, and they perform the same no matter what language (Python, R, Scala or Java) you use with Spark.
In this course, we’ll be using DataFrames, so we won’t be interacting directly with the Spark Context object very much. However, it’s worth knowing that inside pyspark or a notebook, you already have an existing SparkContext in the sc variable. One simple thing we can do with sc is check the version of Spark we’re using:
|
|
Part 3: Using DataFrames and chaining together transformations and actions
Working with your first DataFrames
In Spark, we first create a base DataFrame. We can then apply one or more transformations to that base DataFrame. A DataFrame is immutable, so once it is created, it cannot be changed. As a result, each transformation creates a new DataFrame. Finally, we can apply one or more actions to the DataFrames.
Note that Spark uses lazy evaluation, so transformations are not actually executed until an action occurs.
We will perform several exercises to obtain a better understanding of DataFrames:
- Create a Python collection of 10,000 integers
- Create a Spark DataFrame from that collection
- Subtract one from each value using
map - Perform action
collectto view results - Perform action
countto view counts - Apply transformation
filterand view results withcollect - Learn about lambda functions
- Explore how lazy evaluation works and the debugging challenges that it introduces
A DataFrame consists of a series of Row objects; each Row object has a set of named columns. You can think of a DataFrame as modeling a table, though the data source being processed does not have to be a table.
More formally, a DataFrame must have a schema, which means it must consist of columns, each of which has a name and a type. Some data sources have schemas built into them. Examples include RDBMS databases, Parquet files, and NoSQL databases like Cassandra. Other data sources don’t have computer-readable schemas, but you can often apply a schema programmatically.
(3a) Create a Python collection of 10,000 people
We will use a third-party Python testing library called fake-factory to create a collection of fake person records.
|
|
We’re going to use this factory to create a collection of randomly generated people records. In the next section, we’ll turn that collection into a DataFrame. We’ll use the Spark Row class,
because that will help us define the Spark DataFrame schema. There are other ways to define schemas, though; see
the Spark Programming Guide’s discussion of schema inference for more information. (For instance,
we could also use a Python namedtuple.)
|
|
data is just a normal Python list, containing Python tuples objects. Let’s look at the first item in the list:
|
|
We can check the size of the list using the Python len() function.
|
|
(3b) Distributed data and using a collection to create a DataFrame
In Spark, datasets are represented as a list of entries, where the list is broken up into many different partitions that are each stored on a different machine. Each partition holds a unique subset of the entries in the list. Spark calls datasets that it stores “Resilient Distributed Datasets” (RDDs). Even DataFrames are ultimately represented as RDDs, with additional meta-data.
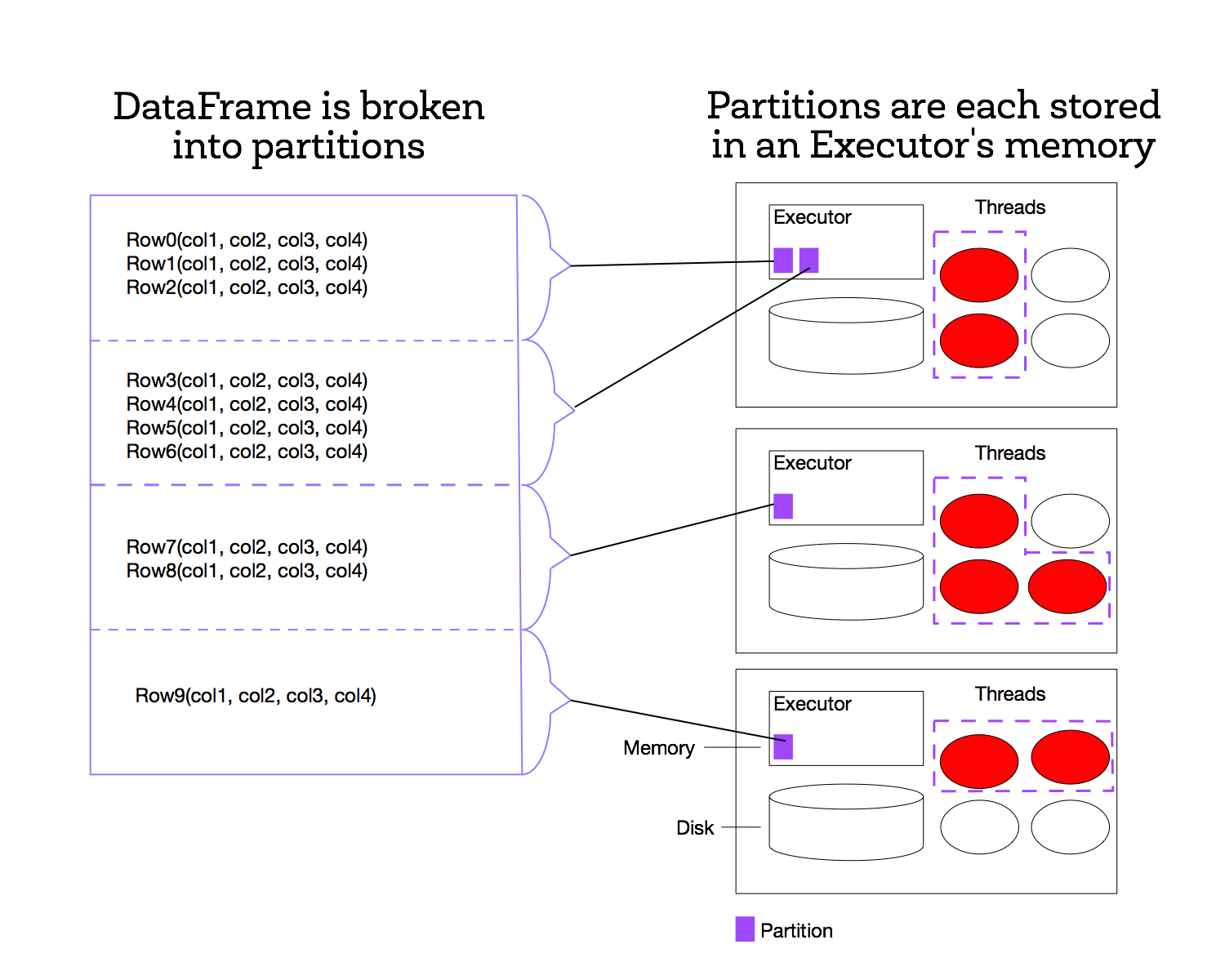
One of the defining features of Spark, compared to other data analytics frameworks (e.g., Hadoop), is that it stores data in memory rather than on disk. This allows Spark applications to run much more quickly, because they are not slowed down by needing to read data from disk. The figure to the right illustrates how Spark breaks a list of data entries into partitions that are each stored in memory on a worker.
To create the DataFrame, we’ll use sqlContext.createDataFrame(), and we’ll pass our array of data in as an argument to that function. Spark will create a new set of input data based on data that is passed in. A DataFrame requires a schema, which is a list of columns, where each column has a name and a type. Our list of data has elements with types (mostly strings, but one integer). We’ll supply the rest of the schema and the column names as the second argument to createDataFrame().
Let’s view the help for createDataFrame().
|
|
Let’s see what type sqlContext.createDataFrame() returned.
|
|
Let’s take a look at the DataFrame’s schema and some of its rows.
|
|
We can register the newly created DataFrame as a named table, using the registerDataFrameAsTable() method.
|
|
What methods can we call on this DataFrame?
|
|
How many partitions will the DataFrame be split into?
|
|
A note about DataFrames and queries
When you use DataFrames or Spark SQL, you are building up a query plan. Each transformation you apply to a DataFrame adds some information to the query plan. When you finally call an action, which triggers execution of your Spark job, several things happen:
- Spark’s Catalyst optimizer analyzes the query plan (called an unoptimized logical query plan) and attempts to optimize it. Optimizations include (but aren’t limited to) rearranging and combining
filter()operations for efficiency, convertingDecimaloperations to more efficient long integer operations, and pushing some operations down into the data source (e.g., afilter()operation might be translated to a SQLWHEREclause, if the data source is a traditional SQL RDBMS). The result of this optimization phase is an optimized logical plan. - Once Catalyst has an optimized logical plan, it then constructs multiple physical plans from it. Specifically, it implements the query in terms of lower level Spark RDD operations.
- Catalyst chooses which physical plan to use via cost optimization. That is, it determines which physical plan is the most efficient (or least expensive), and uses that one.
- Finally, once the physical RDD execution plan is established, Spark actually executes the job.
You can examine the query plan using the explain() function on a DataFrame. By default, explain() only shows you the final physical plan; however, if you pass it an argument of True, it will show you all phases.
(If you want to take a deeper dive into how Catalyst optimizes DataFrame queries, this blog post, while a little old, is an excellent overview: Deep Dive into Spark SQL’s Catalyst Optimizer.)
Let’s add a couple transformations to our DataFrame and look at the query plan on the resulting transformed DataFrame. Don’t be too concerned if it looks like gibberish. As you gain more experience with Apache Spark, you’ll begin to be able to use explain() to help you understand more about your DataFrame operations.
|
|
(3c): Subtract one from each value using select
So far, we’ve created a distributed DataFrame that is split into many partitions, where each partition is stored on a single machine in our cluster. Let’s look at what happens when we do a basic operation on the dataset. Many useful data analysis operations can be specified as “do something to each item in the dataset”. These data-parallel operations are convenient because each item in the dataset can be processed individually: the operation on one entry doesn’t effect the operations on any of the other entries. Therefore, Spark can parallelize the operation.
One of the most common DataFrame operations is select(), and it works more or less like a SQL SELECT statement: You can select specific columns from the DataFrame, and you can even use select() to create new columns with values that are derived from existing column values. We can use select() to create a new column that decrements the value of the existing age column.
select() is a transformation. It returns a new DataFrame that captures both the previous DataFrame and the operation to add to the query (select, in this case). But it does not actually execute anything on the cluster. When transforming DataFrames, we are building up a query plan. That query plan will be optimized, implemented (in terms of RDDs), and executed by Spark only when we call an action.
|
|
Let’s take a look at the query plan.
|
|
(3d) Use collect to view results
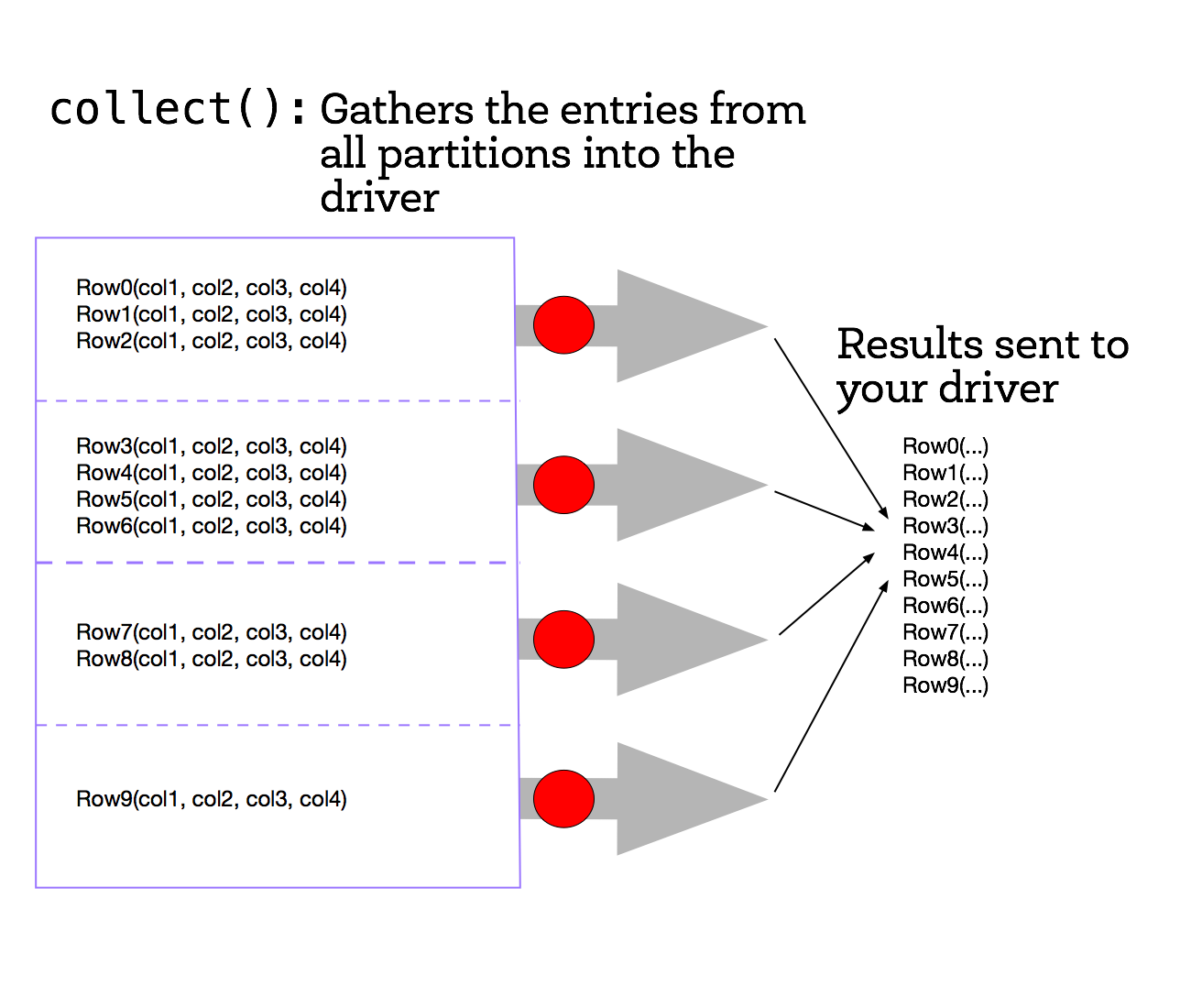
To see a list of elements decremented by one, we need to create a new list on the driver from the the data distributed in the executor nodes. To do this we can call the collect() method on our DataFrame. collect() is often used after transformations to ensure that we are only returning a small amount of data to the driver. This is done because the data returned to the driver must fit into the driver’s available memory. If not, the driver will crash.
The collect() method is the first action operation that we have encountered. Action operations cause Spark to perform the (lazy) transformation operations that are required to compute the values returned by the action. In our example, this means that tasks will now be launched to perform the createDataFrame, select, and collect operations.
In the diagram, the dataset is broken into four partitions, so four collect() tasks are launched. Each task collects the entries in its partition and sends the result to the driver, which creates a list of the values, as shown in the figure below.
Now let’s run collect() on subDF.
|
|
A better way to visualize the data is to use the show() method. If you don’t tell show() how many rows to display, it displays 20 rows.
|
|
If you’d prefer that show() not truncate the data, you can tell it not to:
|
|
In Databricks, there’s an even nicer way to look at the values in a DataFrame: The display() helper function.
|
|
(3e) Use count to get total
One of the most basic jobs that we can run is the count() job which will count the number of elements in a DataFrame, using the count() action. Since select() creates a new DataFrame with the same number of elements as the starting DataFrame, we expect that applying count() to each DataFrame will return the same result.
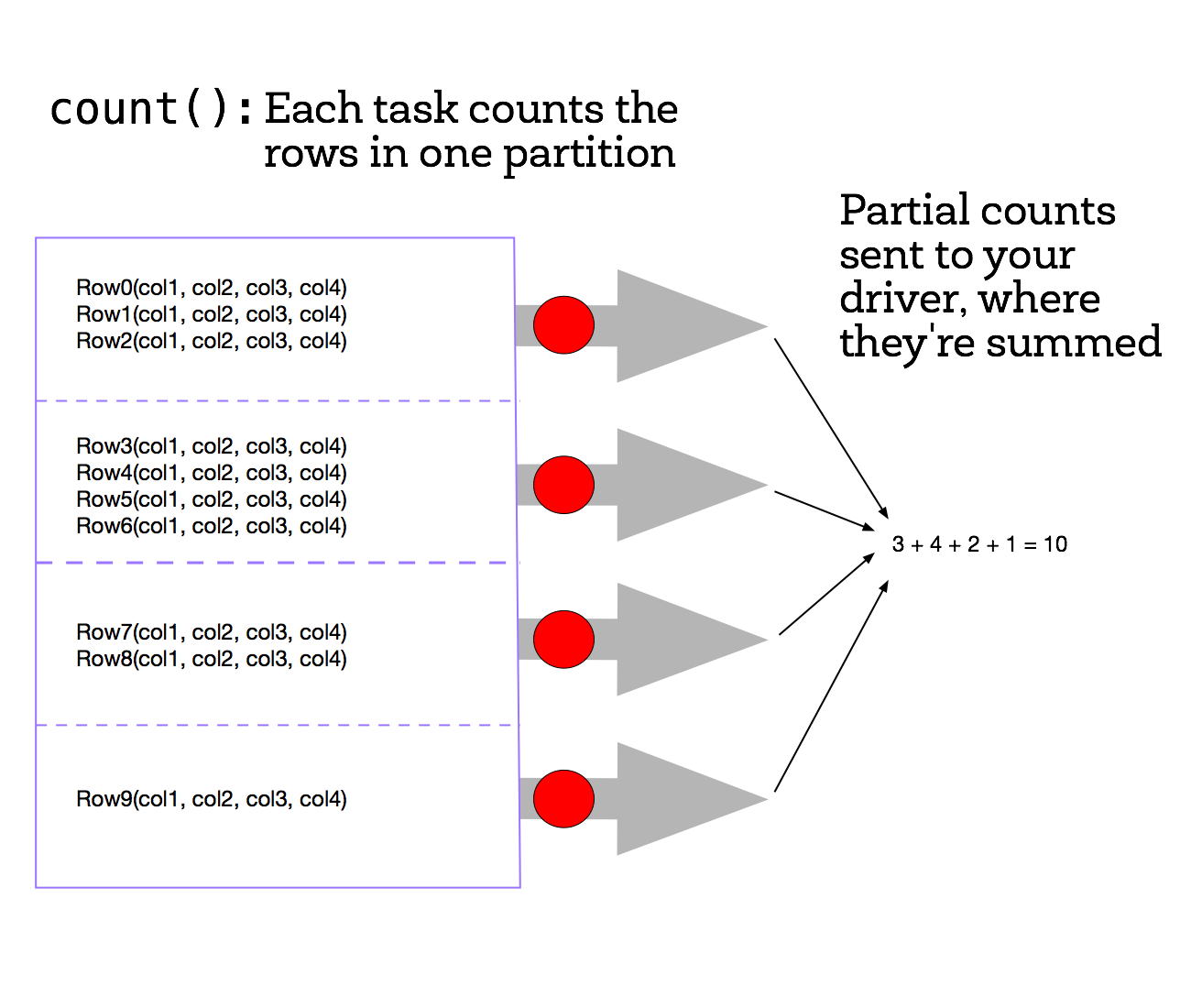
Note that because count() is an action operation, if we had not already performed an action with collect(), then Spark would now perform the transformation operations when we executed count().
Each task counts the entries in its partition and sends the result to your SparkContext, which adds up all of the counts. The figure on the right shows what would happen if we ran count() on a small example dataset with just four partitions.
|
|
(3f) Apply transformation filter and view results with collect
Next, we’ll create a new DataFrame that only contains the people whose ages are less than 10. To do this, we’ll use the filter() transformation. (You can also use where(), an alias for filter(), if you prefer something more SQL-like). The filter() method is a transformation operation that creates a new DataFrame from the input DataFrame, keeping only values that match the filter expression.
The figure shows how this might work on the small four-partition dataset.
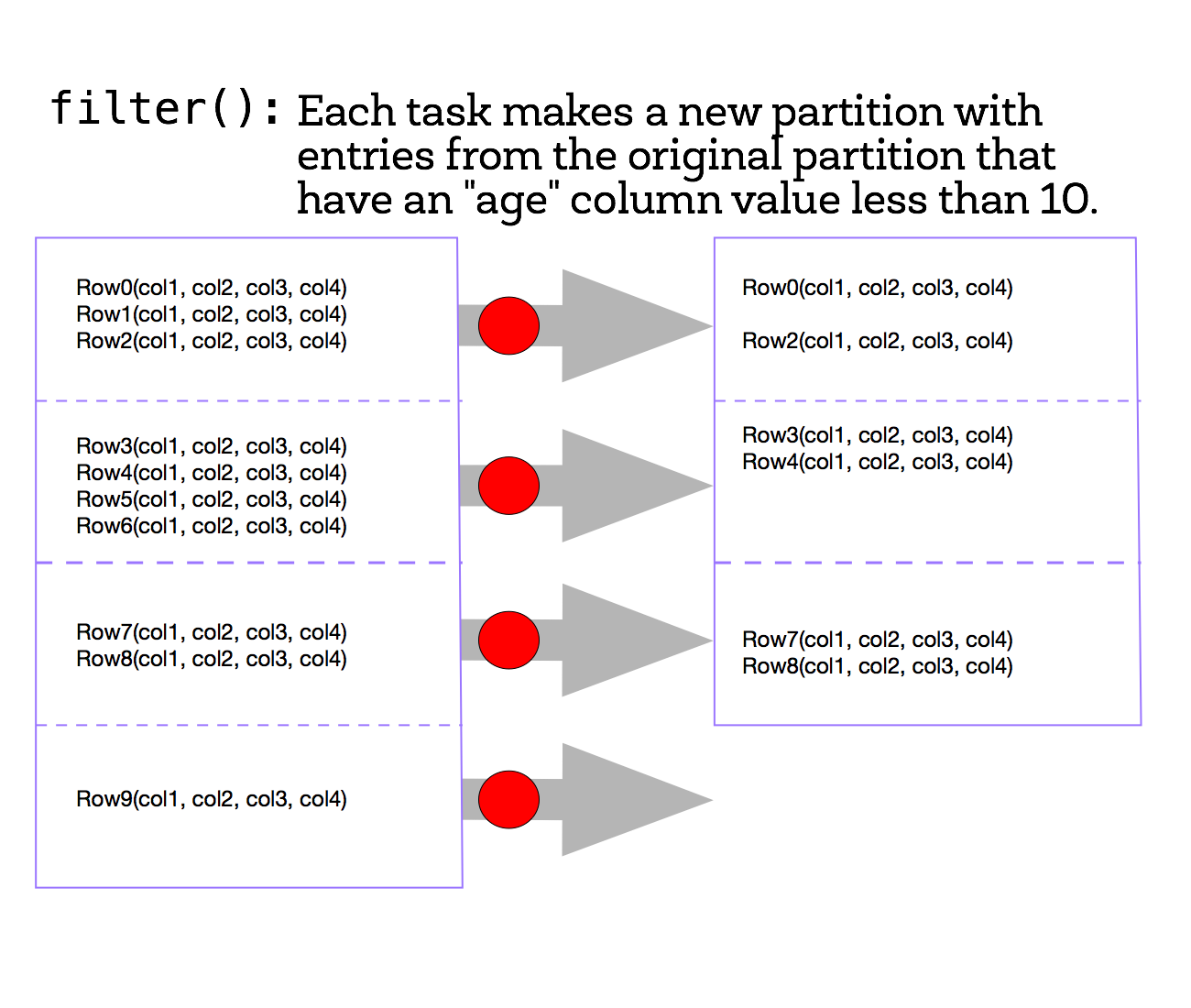
To view the filtered list of elements less than 10, we need to create a new list on the driver from the distributed data on the executor nodes. We use the collect() method to return a list that contains all of the elements in this filtered DataFrame to the driver program.
|
|
(These are some seriously precocious children…)
Part 4: Python Lambda functions and User Defined Functions
Python supports the use of small one-line anonymous functions that are not bound to a name at runtime.
lambda functions, borrowed from LISP, can be used wherever function objects are required. They are syntactically restricted to a single expression. Remember that lambda functions are a matter of style and using them is never required - semantically, they are just syntactic sugar for a normal function definition. You can always define a separate normal function instead, but using a lambda function is an equivalent and more compact form of coding. Ideally you should consider using lambda functions where you want to encapsulate non-reusable code without littering your code with one-line functions.
Here, instead of defining a separate function for the filter() transformation, we will use an inline lambda() function and we will register that lambda as a Spark User Defined Function (UDF). A UDF is a special wrapper around a function, allowing the function to be used in a DataFrame query.
|
|
Part 5: Additional DataFrame actions
Let’s investigate some additional actions:
One useful thing to do when we have a new dataset is to look at the first few entries to obtain a rough idea of what information is available. In Spark, we can do that using actions like first(), take(), and show(). Note that for the first() and take() actions, the elements that are returned depend on how the DataFrame is partitioned.
Instead of using the collect() action, we can use the take(n) action to return the first n elements of the DataFrame. The first() action returns the first element of a DataFrame, and is equivalent to take(1)[0].
|
|
This looks better:
|
|
Part 6: Additional DataFrame transformations
(6a) orderBy
orderBy() allows you to sort a DataFrame by one or more columns, producing a new DataFrame.
For example, let’s get the first five oldest people in the original (unfiltered) DataFrame. We can use the orderBy() transformation. orderBy takes one or more columns, either as names (strings) or as Column objects. To get a Column object, we use one of two notations on the DataFrame:
- Pandas-style notation:
filteredDF.age - Subscript notation:
filteredDF['age']
Both of those syntaxes return a Column, which has additional methods like desc() (for sorting in descending order) or asc() (for sorting in ascending order, which is the default).
Here are some examples:
|
|
|
|
Let’s reverse the sort order. Since ascending sort is the default, we can actually use a Column object expression or a simple string, in this case. The desc() and asc() methods are only defined on Column. Something like orderBy('age'.desc()) would not work, because there’s no desc() method on Python string objects. That’s why we needed the column expression. But if we’re just using the defaults, we can pass a string column name into orderBy(). This is sometimes easier to read.
|
|
(6b) distinct and dropDuplicates
distinct() filters out duplicate rows, and it considers all columns. Since our data is completely randomly generated (by fake-factory), it’s extremely unlikely that there are any duplicate rows:
|
|
To demonstrate distinct(), let’s create a quick throwaway dataset.
|
|
Note that one of the (“Joe”, 1) rows was deleted, but both rows with name “Anna” were kept, because all columns in a row must match another row for it to be considered a duplicate.
dropDuplicates() is like distinct(), except that it allows us to specify the columns to compare. For instance, we can use it to drop all rows where the first name and last name duplicates (ignoring the occupation and age columns).
|
|
(6c) drop
drop() is like the opposite of select(): Instead of selecting specific columns from a DataFrame, it drops a specifed column from a DataFrame.
Here’s a simple use case: Suppose you’re reading from a 1,000-column CSV file, and you have to get rid of five of the columns. Instead of selecting 995 of the columns, it’s easier just to drop the five you don’t want.
|
|
(6d) groupBy
[groupBy()]((http://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.DataFrame.groupBy) is one of the most powerful transformations. It allows you to perform aggregations on a DataFrame.
Unlike other DataFrame transformations, groupBy() does not return a DataFrame. Instead, it returns a special GroupedData object that contains various aggregation functions.
The most commonly used aggregation function is count(), but there are others (like sum(), max(), and avg().
These aggregation functions typically create a new column and return a new DataFrame.
|
|
We can also use groupBy() to do aother useful aggregations:
|
|
(6e) sample (optional)
When analyzing data, the sample() transformation is often quite useful. It returns a new DataFrame with a random sample of elements from the dataset. It takes in a withReplacement argument, which specifies whether it is okay to randomly pick the same item multiple times from the parent DataFrame (so when withReplacement=True, you can get the same item back multiple times). It takes in a fraction parameter, which specifies the fraction elements in the dataset you want to return. (So a fraction value of 0.20 returns 20% of the elements in the DataFrame.) It also takes an optional seed parameter that allows you to specify a seed value for the random number generator, so that reproducible results can be obtained.
|
|
Part 7: Caching DataFrames and storage options
(7a) Caching DataFrames
For efficiency Spark keeps your DataFrames in memory. (More formally, it keeps the RDDs that implement your DataFrames in memory.) By keeping the contents in memory, Spark can quickly access the data. However, memory is limited, so if you try to keep too many partitions in memory, Spark will automatically delete partitions from memory to make space for new ones. If you later refer to one of the deleted partitions, Spark will automatically recreate it for you, but that takes time.
So, if you plan to use a DataFrame more than once, then you should tell Spark to cache it. You can use the cache() operation to keep the DataFrame in memory. However, you must still trigger an action on the DataFrame, such as collect() or count() before the caching will occur. In other words, cache() is lazy: It merely tells Spark that the DataFrame should be cached when the data is materialized. You have to run an action to materialize the data; the DataFrame will be cached as a side effect. The next time you use the DataFrame, Spark will use the cached data, rather than recomputing the DataFrame from the original data.
You can see your cached DataFrame in the “Storage” section of the Spark web UI. If you click on the name value, you can see more information about where the the DataFrame is stored.
|
|
(7b) Unpersist and storage options
Spark automatically manages the partitions cached in memory. If it has more partitions than available memory, by default, it will evict older partitions to make room for new ones. For efficiency, once you are finished using cached DataFrame, you can optionally tell Spark to stop caching it in memory by using the DataFrame’s unpersist() method to inform Spark that you no longer need the cached data.
** Advanced: ** Spark provides many more options for managing how DataFrames cached. For instance, you can tell Spark to spill cached partitions to disk when it runs out of memory, instead of simply throwing old ones away. You can explore the API for DataFrame’s persist() operation using Python’s help() command. The persist() operation, optionally, takes a pySpark StorageLevel object.
|
|
** Part 8: Debugging Spark applications and lazy evaluation **
How Python is Executed in Spark
Internally, Spark executes using a Java Virtual Machine (JVM). pySpark runs Python code in a JVM using Py4J. Py4J enables Python programs running in a Python interpreter to dynamically access Java objects in a Java Virtual Machine. Methods are called as if the Java objects resided in the Python interpreter and Java collections can be accessed through standard Python collection methods. Py4J also enables Java programs to call back Python objects.
Because pySpark uses Py4J, coding errors often result in a complicated, confusing stack trace that can be difficult to understand. In the following section, we’ll explore how to understand stack traces.
(8a) Challenges with lazy evaluation using transformations and actions
Spark’s use of lazy evaluation can make debugging more difficult because code is not always executed immediately. To see an example of how this can happen, let’s first define a broken filter function.
Next we perform a filter() operation using the broken filtering function. No error will occur at this point due to Spark’s use of lazy evaluation.
The filter() method will not be executed until an action operation is invoked on the DataFrame. We will perform an action by using the count() method to return a list that contains all of the elements in this DataFrame.
|
|
(8b) Finding the bug
When the filter() method is executed, Spark calls the UDF. Since our UDF has an error in the underlying filtering function brokenTen(), an error occurs.
Scroll through the output “Py4JJavaError Traceback (most recent call last)” part of the cell and first you will see that the line that generated the error is the count() method line. There is nothing wrong with this line. However, it is an action and that caused other methods to be executed. Continue scrolling through the Traceback and you will see the following error line:
NameError: global name 'val' is not defined
Looking at this error line, we can see that we used the wrong variable name in our filtering function brokenTen().
(8c) Moving toward expert style
As you are learning Spark, I recommend that you write your code in the form:
|
|
Using this style will make debugging your code much easier as it makes errors easier to localize - errors in your transformations will occur when the next action is executed.
Once you become more experienced with Spark, you can write your code with the form: df.transformation1().transformation2().action()
We can also use lambda() functions instead of separately defined functions when their use improves readability and conciseness.
|
|
(8d) Readability and code style
To make the expert coding style more readable, enclose the statement in parentheses and put each method, transformation, or action on a separate line.
|
|